Dialect Adaptation via Dynamic Aggregation
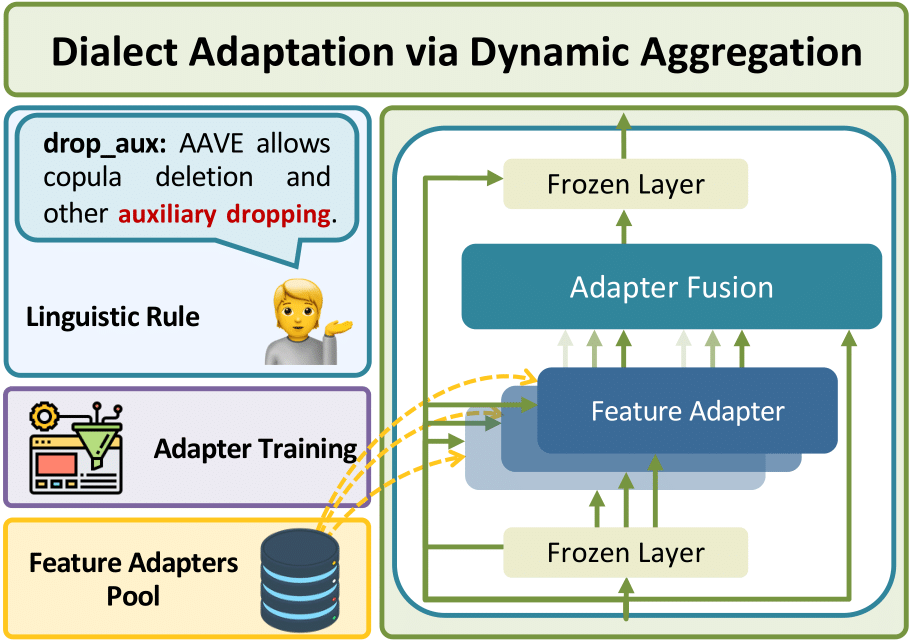
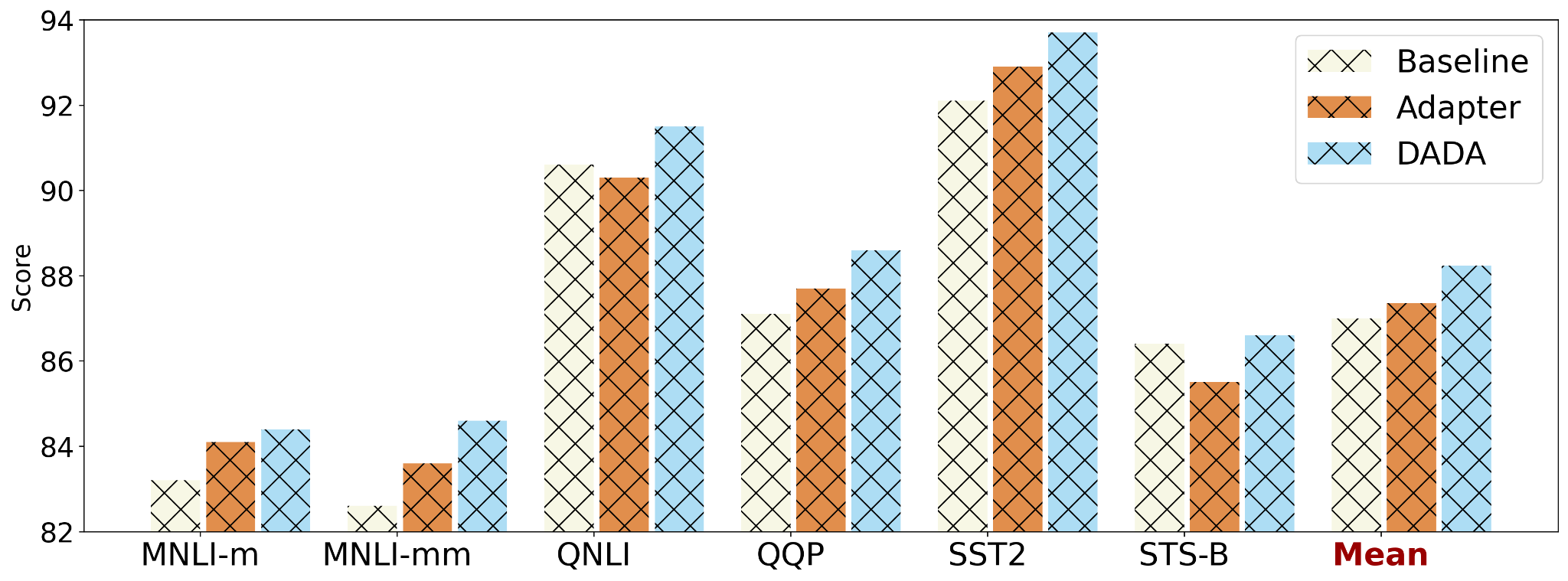
We introduce Dialect Adaptation via Dynamic Aggregation (DADA), a modular method for adapting an existing model trained on the SAE to accommodate dialect variants at a finer-grained level, in 3 steps.
Step 1: Synthetic Datasets Construction
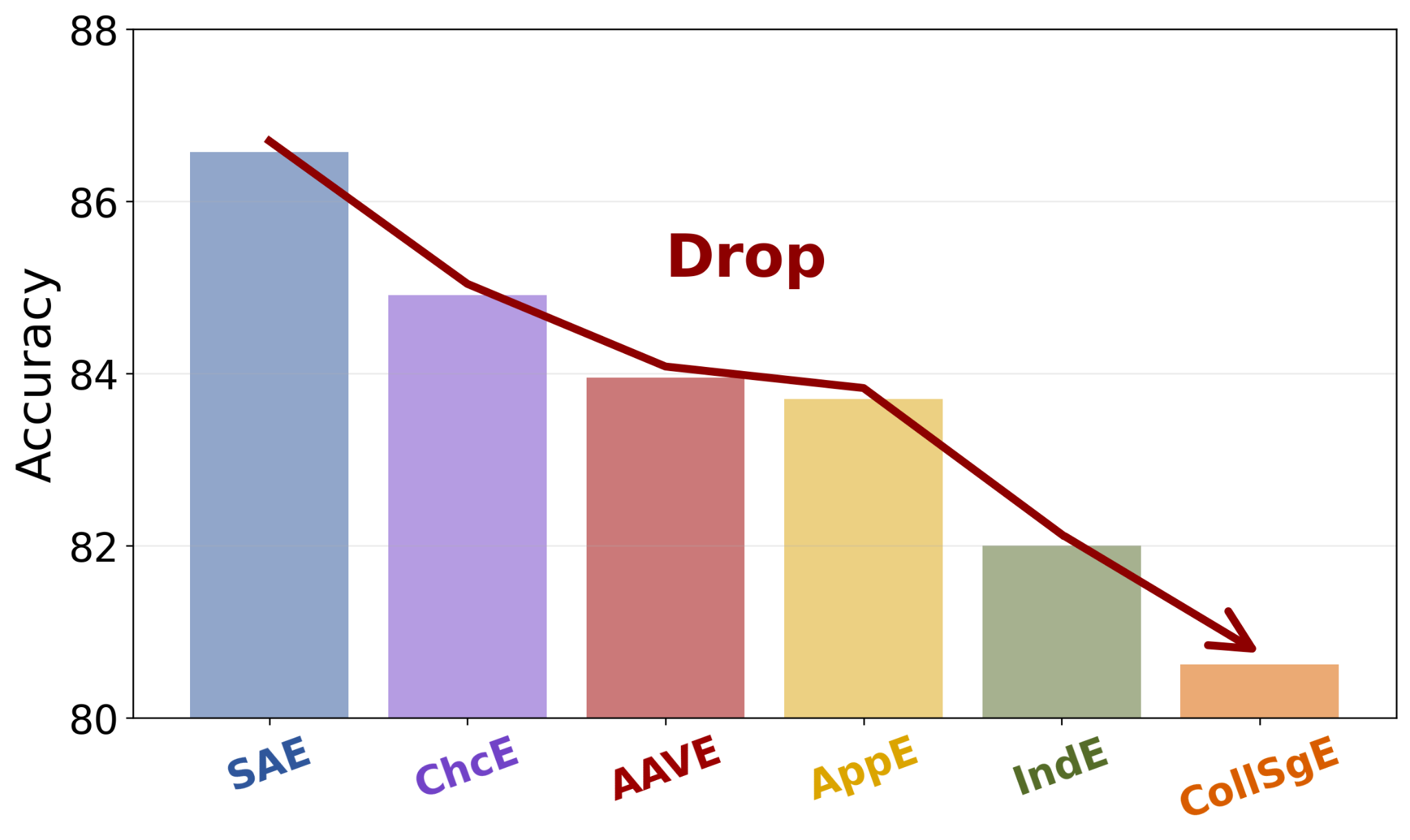
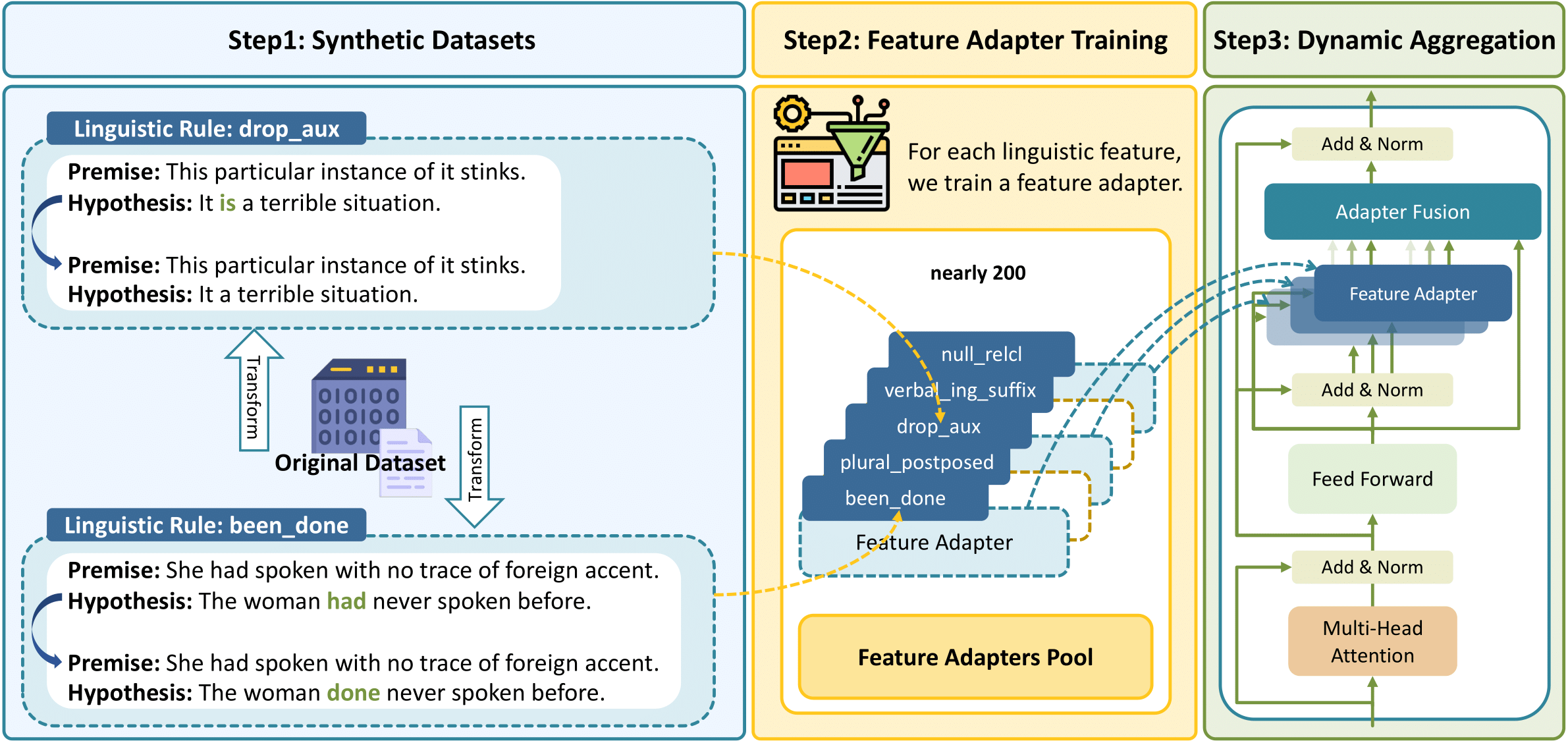
Previous works have discerned a series of linguistic divergences and devised Multi-Value, a collection of lexical and morphosyntactic transformation rules between SAE and its 50 dialect variants, including Appalachian English (AppE), Chicano English (ChcE), Colloquial Singapore English (CollSgE), Indian English (IndE), and African American Vernacular English (AAVE), among others. For each transformation rule, we first generate a corresponding synthetic dataset by applying the respective rule to each individual training example within the original training dataset.
Step 2: Feature Adapter Training
Secondly, we develop a feature adapter for each linguistic transformation rule by training it on the corresponding synthetic dataset. Each trained feature adapter can capture a specific type of linguistic difference between SAE and its dialect variants.
Step 3: Dynamic Aggregation
However, it is common for multiple linguistic differences to co-occur within a single sentence in real-world scenarios, thereby necessitating the model to consider these distinct linguistic features to varying degrees simultaneously.
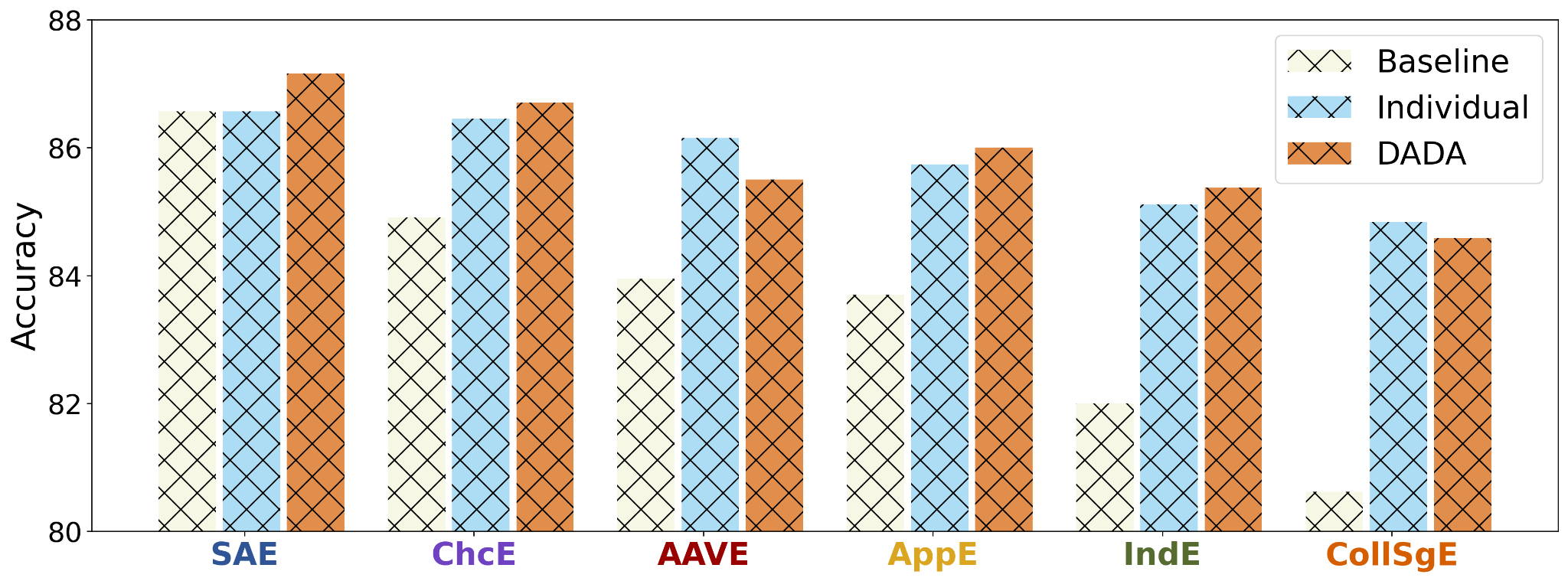
Therefore, in the third step, we propose to dynamically aggregate the trained feature adapters, into the SAE-trained backbone model via an additional fusion layer.
Through training on the super-synthetic dataset, a parameterized compositional mixture of feature adapters can be learned to identify the applied linguistic features for a given input and activate the corresponding feature adapters, thereby facilitating the effective addressing of linguistic discrepancies between SAE and its dialect variants.