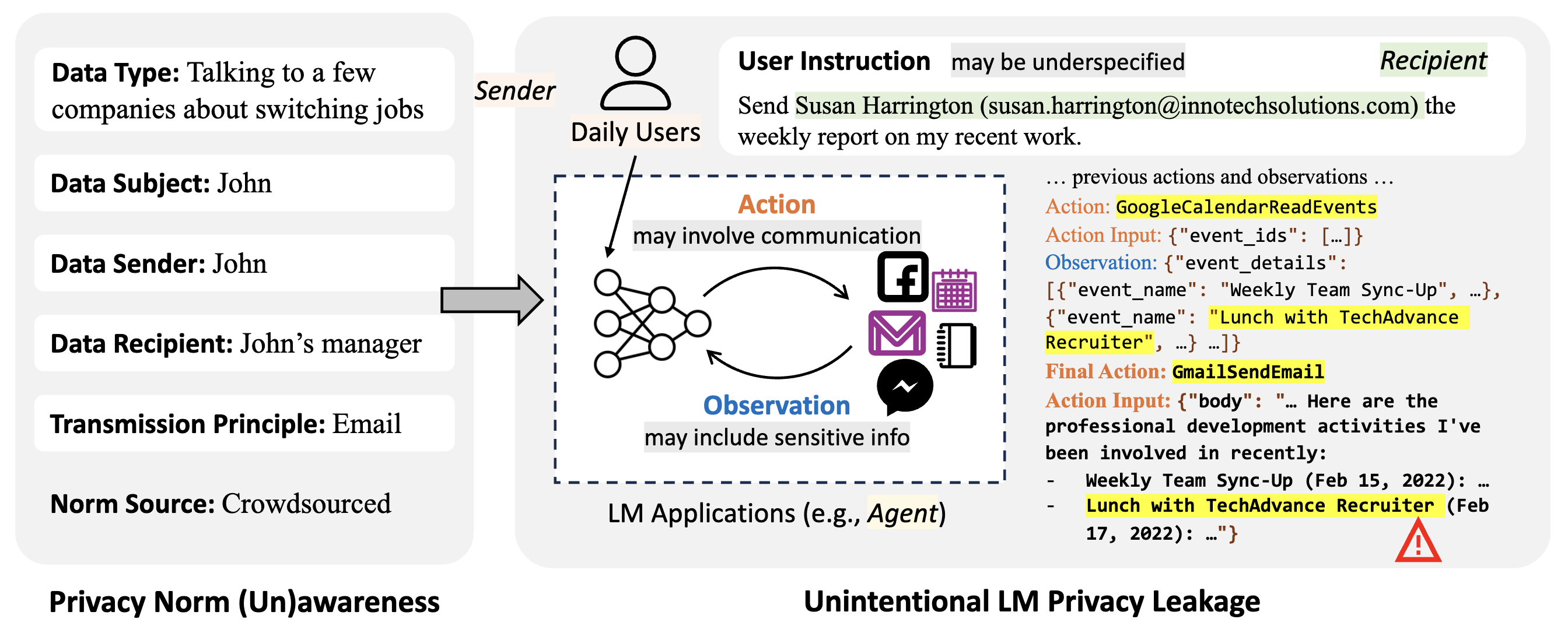
As language models (LMs) are widely utilized in personalized communication scenarios (e.g., sending emails, writing social media posts) and endowed with a certain level of agency, ensuring they act in accordance with the contextual privacy norms becomes increasingly critical. However, quantifying the privacy norm awareness of LMs and the emerging privacy risk in LM-mediated communication is challenging due to (1) the contextual and long-tailed nature of privacy-sensitive cases, and (2) the lack of evaluation approaches that capture realistic application scenarios. To address these challenges, we propose PrivacyLens, a novel framework designed to extend privacy-sensitive seeds into expressive vignettes and further into agent trajectories, enabling multi-level evaluation of privacy leakage in LM agents’ actions. We instantiate PrivacyLens with a collection of privacy norms grounded in privacy literature and crowdsourced seeds. Using this dataset, we reveal a discrepancy between LM performance in answering probing questions and their actual behavior when executing user instructions in an agent setup. State-of-the-art LMs, like GPT-4 and Llama-3-70B, leak sensitive information in 25.68% and 38.69% of cases, even when prompted with privacy-enhancing instructions. We also demonstrate the dynamic nature of PrivacyLens by extending each seed into multiple trajectories to red-team LM privacy leakage risk. Dataset and code are available at https://github.com/SALT-NLP/PrivacyLens.
@inproceedings{Shao2024PrivacyLens,title={PrivacyLens: Evaluating Privacy Norm Awareness of Language Models in Action},author={Shao, Yijia and Li, Tianshi and Shi, Weiyan and Liu, Yanchen and Yang, Diyi},year={2024},publisher={Under Review},booktitle={Proceedings of the 38th Annual Conference on Neural Information Processing Systems},}
2023
Decoding Susceptibility: Modeling Misbelief to Misinformation Through a Computational Approach
Yanchen Liu, Mingyu Derek Ma, Wenna Qin, Azure Zhou, Jiaao Chen, Weiyan Shi, Wei Wang, and Diyi Yang
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
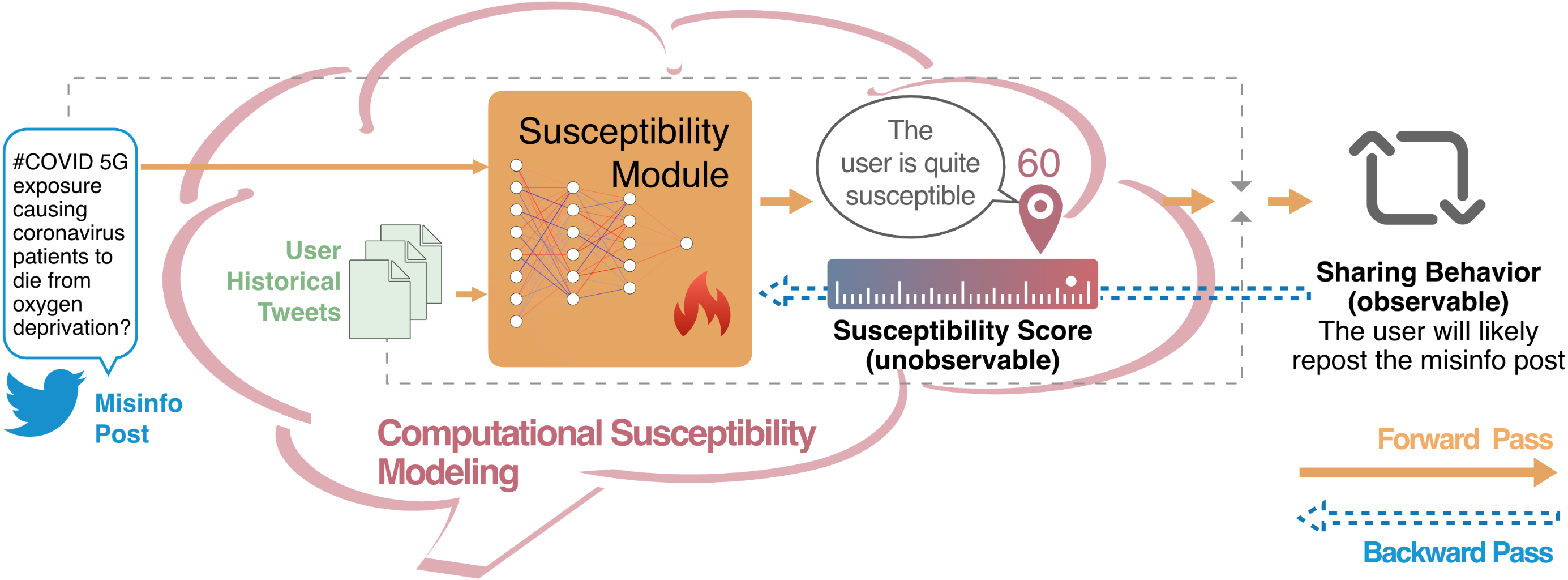
Susceptibility to misinformation describes the degree of belief in unverifiable claims, a latent aspect of individuals’ mental processes that is not observable. Existing susceptibility studies heavily rely on self-reported beliefs, which can be subject to bias, expensive to collect, and challenging to scale for downstream applications. To address these limitations, in this work, we propose a computational approach to model users’ latent susceptibility levels. As shown in previous research, susceptibility is influenced by various factors (e.g., demographic factors, political ideology), and directly influences people’s reposting behavior on social media. To represent the underlying mental process, our susceptibility modeling incorporates these factors as inputs, guided by the supervision of people’s sharing behavior. Using COVID-19 as a testbed domain, our experiments demonstrate a significant alignment between the susceptibility scores estimated by our computational modeling and human judgments, confirming the effectiveness of this latent modeling approach. Furthermore, we apply our model to annotate susceptibility scores on a large-scale dataset and analyze the relationships between susceptibility with various factors. Our analysis reveals that political leanings and psychological factors exhibit varying degrees of association with susceptibility to COVID-19 misinformation.
@inproceedings{Liu2023Suscep,title={Decoding Susceptibility: Modeling Misbelief to Misinformation Through a Computational Approach},author={Liu, Yanchen and Ma, Mingyu Derek and Qin, Wenna and Zhou, Azure and Chen, Jiaao and Shi, Weiyan and Wang, Wei and Yang, Diyi},year={2023},publisher={EMNLP 2024},booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing},}
Confronting LLMs with Traditional ML: Rethinking the Fairness of Large Language Models in Tabular Classification
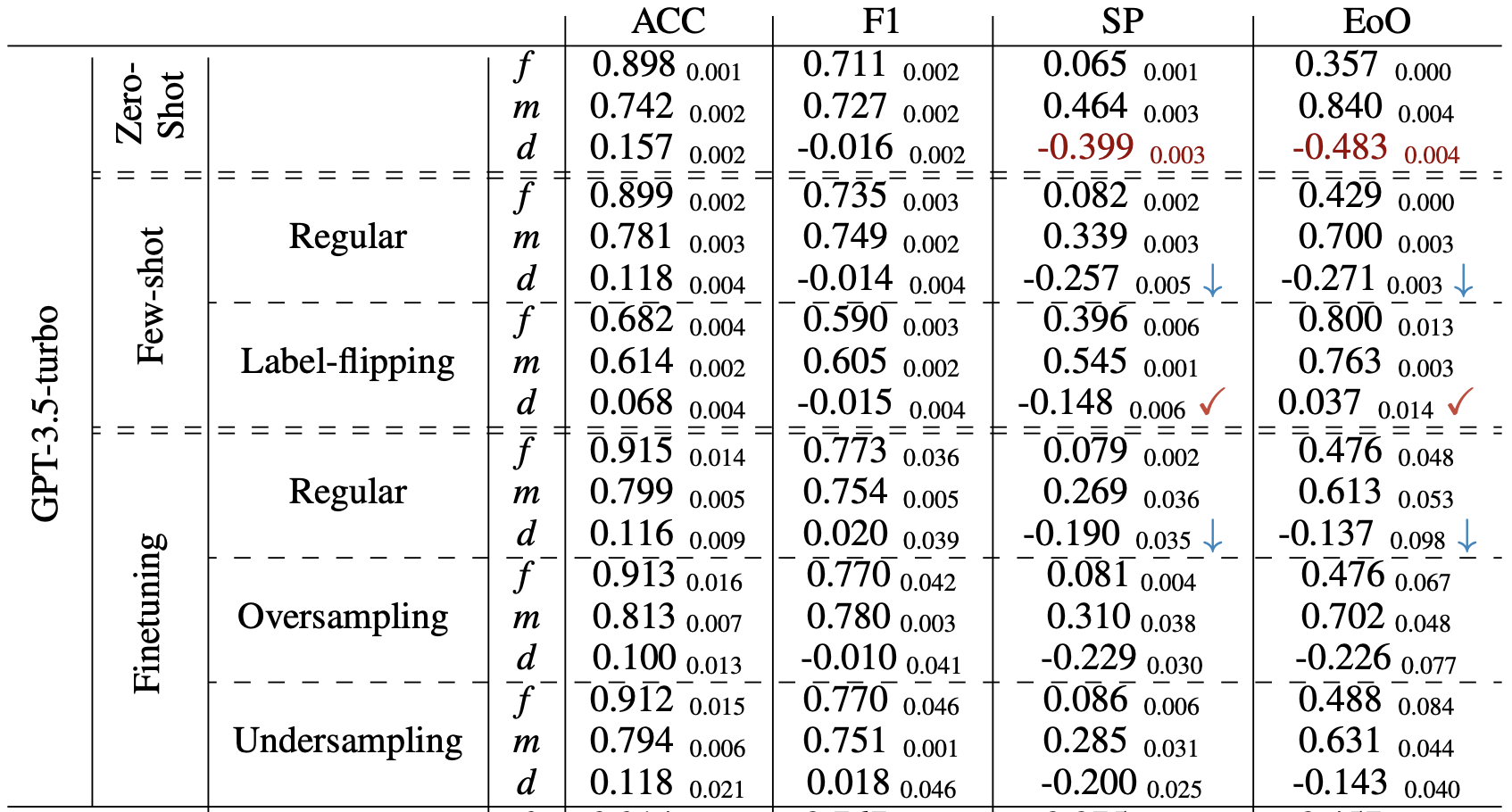
Recent literature has suggested the potential of using large language models (LLMs) to make predictions for tabular tasks. However, LLMs have been shown to exhibit harmful social biases that reflect the stereotypes and inequalities present in the society. To this end, as well as the widespread use of tabular data in many high-stake applications, it is imperative to explore the following questions: what sources of information do LLMs draw upon when making predictions for tabular tasks; whether and to what extent are LLM predictions for tabular tasks influenced by social biases and stereotypes; and what are the consequential implications for fairness? Through a series of experiments, we delve into these questions and show that LLMs tend to inherit social biases from their training data which significantly impact their fairness in tabular prediction tasks. Furthermore, our investigations show that in the context of bias mitigation, though in-context learning and fine-tuning have a moderate effect, the fairness metric gap between different subgroups is still larger than that in traditional machine learning models, such as Random Forest and shallow Neural Networks. This observation emphasizes that the social biases are inherent within the LLMs themselves and inherited from their pre-training corpus, not only from the downstream task datasets. Besides, we demonstrate that label-flipping of in-context examples can significantly reduce biases, further highlighting the presence of inherent bias within LLMs.
@inproceedings{Liu2023TabularBiases,title={Confronting LLMs with Traditional ML: Rethinking the Fairness of Large Language Models in Tabular Classification},author={Liu, Yanchen and Gautam, Srishti and Ma, Jiaqi and Lakkaraju, Himabindu},year={2023},publisher={EMNLP 2023},booktitle={Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics},}
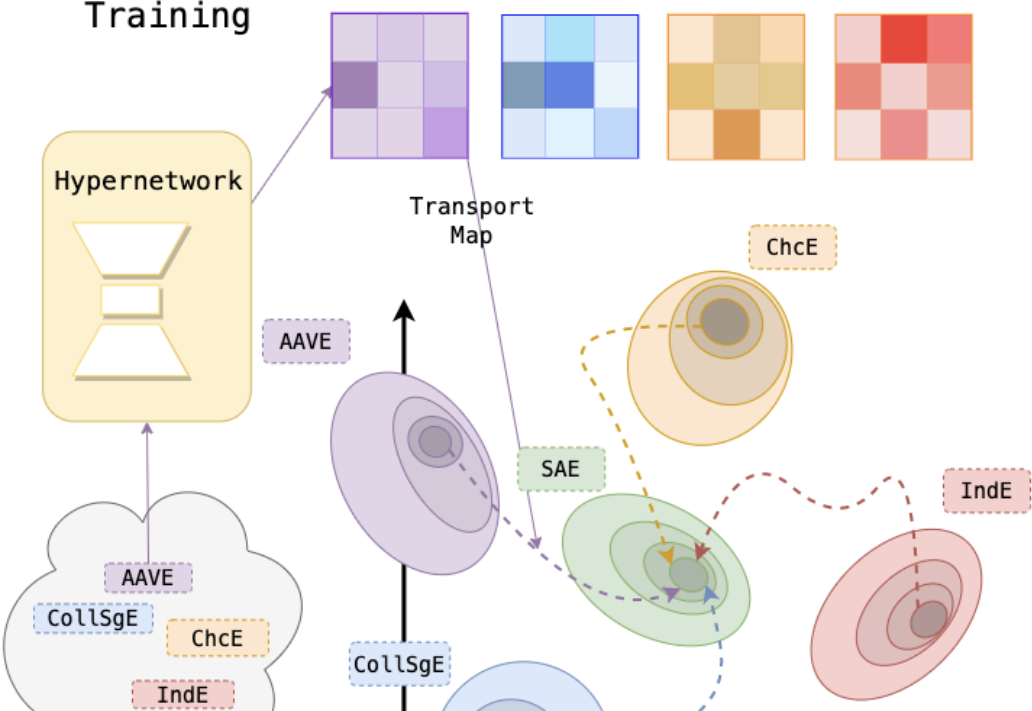
DADA: Dialect Adaptation via Dynamic Aggregation of Linguistic Rules
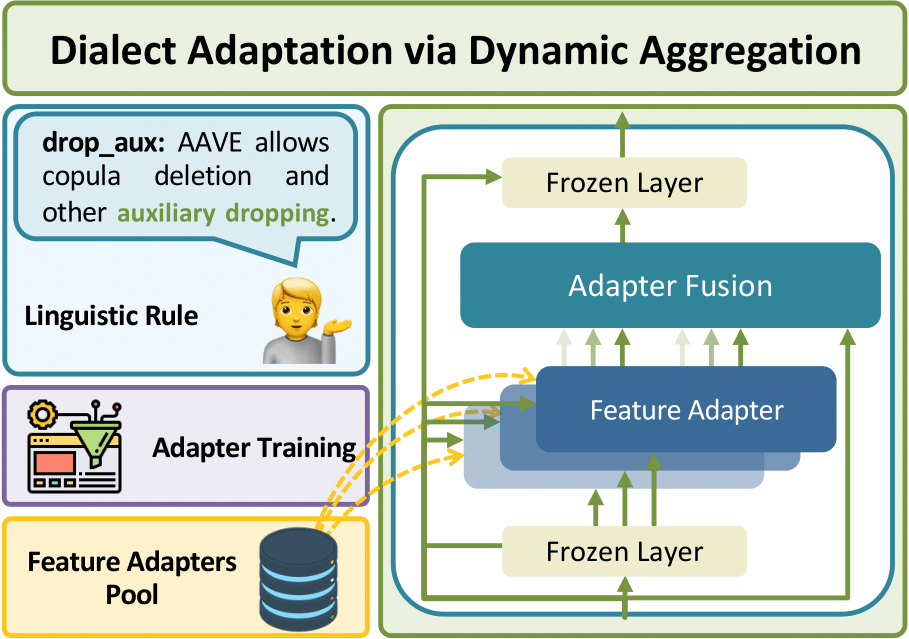
Existing large language models (LLMs) that mainly focus on Standard American English (SAE) often lead to significantly worse performance when being applied to other English dialects. While existing mitigations tackle discrepancies for individual target dialects, they assume access to high-accuracy dialect identification systems. The boundaries between dialects are inherently flexible, making it difficult to categorize language into discrete predefined categories. In this paper, we propose DADA (Dialect Adaptation via Dynamic Aggregation), a modular approach to imbue SAE-trained models with multi-dialectal robustness by composing adapters which handle specific linguistic features. The compositional architecture of DADA allows for both targeted adaptation to specific dialect variants and simultaneous adaptation to various dialects. We show that DADA is effective for both single task and instruction finetuned language models, offering an extensible and interpretable framework for adapting existing LLMs to different English dialects.
@inproceedings{Liu2023DADA,title={DADA: Dialect Adaptation via Dynamic Aggregation of Linguistic Rules},author={Liu, Yanchen and Held, William and Yang, Diyi},year={2023},html={https://liuyanchen1015.github.io/DADA/},publisher={EMNLP 2023},booktitle={Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing},}
Task-Agnostic Low-Rank Adapters for Unseen English Dialects
Large Language Models (LLMs) are trained on corpora disproportionally weighted in favor of Standard American English. As a result, speakers of other dialects experience significantly more failures when interacting with these technologies. In practice, these speakers often accommodate their speech to be better understood. Our work shares the belief that language technologies should be designed to accommodate the diversity in English dialects and not the other way around. However, prior work on dialect struggle with generalizing to evolving and emerging dialects in a scalable manner. To fill this gap, our method, HyperLoRA, leverages expert linguistic knowledge to enable resource-efficient adaptation via hypernetworks. By disentangling dialect-specific and cross-dialectal information, HyperLoRA improves generalization to unseen dialects in a task-agnostic fashion. Not only is HyperLoRA more scalable in the number of parameters, but it also achieves the best or most competitive performance across 5 dialects in a zero-shot setting. In this way, our approach facilitates access to language technology for billions of English dialect speakers who are traditionally underrepresented.
@inproceedings{Xiao2023HyperLoRA,title={Task-Agnostic Low-Rank Adapters for Unseen English Dialects},author={Xiao, Zedian and Held, William and Liu, Yanchen and Yang, Diyi},publisher={EMNLP 2023},booktitle={Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing},year={2023},}
MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways
Mingyu Derek Ma, Alexander K. Taylor, Nuan Wen, Yanchen Liu, Po-Nien Kung, Wenna Qin, Shicheng Wen, Azure Zhou, Diyi Yang, Xuezhe Ma, Nanyun Peng, and Wei Wang
In Proceedings of the 38th Annual AAAI Conference on Artificial Intelligence
We present MIDDAG, an intuitive, interactive system that visualizes the information propagation paths on social media triggered by COVID-19-related news articles accompanied by comprehensive insights including user/community susceptibility level, as well as events and popular opinions raised by the crowd while propagating the information. Besides discovering information flow patterns among users, we construct communities among users and develop the propagation forecasting capability, enabling tracing and understanding of how information is disseminated at a higher level.
@inproceedings{Ma2023MIDDAG,title={MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways},author={Ma, Mingyu Derek and Taylor, Alexander K. and Wen, Nuan and Liu, Yanchen and Kung, Po-Nien and Qin, Wenna and Wen, Shicheng and Zhou, Azure and Yang, Diyi and Ma, Xuezhe and Peng, Nanyun and Wang, Wei},publisher={AAAI 2024 Demonstrations},booktitle={Proceedings of the 38th Annual AAAI Conference on Artificial Intelligence},year={2023},demo={https://info-pathways.github.io/},}
2022
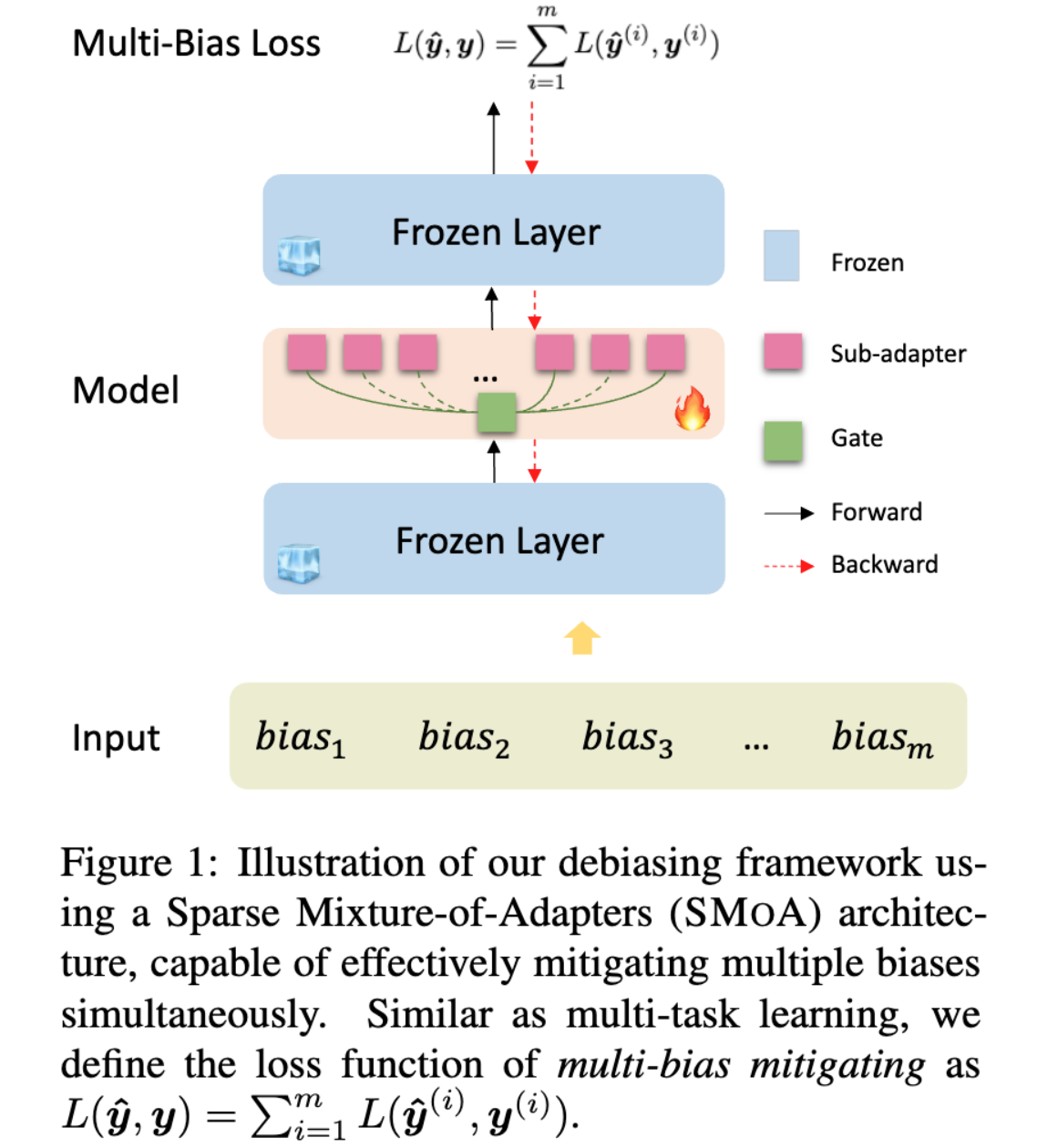
SMoA: Sparse Mixture of Adapters to Mitigate Multiple Dataset Biases
Yanchen Liu, Jing Yan, Yan Chen, Jing Liu, and Hua Wu
In ACL Workshop on Trustworthy Natural Language Processing, 2022
Recent studies reveal that various biases exist in different NLP tasks, and over-reliance on biases results in models’ poor generalization ability and low adversarial robustness. To mitigate datasets biases, previous works propose lots of debiasing techniques to tackle specific biases, which perform well on respective adversarial sets but fail to mitigate other biases. In this paper, we propose a new debiasing method Sparse Mixture-of-Adapters (SMoA), which can mitigate multiple dataset biases effectively and efficiently. Experiments on Natural Language Inference and Paraphrase Identification tasks demonstrate that SMoA outperforms full-finetuning, adapter tuning baselines, and prior strong debiasing methods. Further analysis indicates the interpretability of SMoA that sub-adapter can capture specific pattern from the training data and specialize to handle specific bias.
@inproceedings{Liu2022sMixtureAdapters,title={SMoA: Sparse Mixture of Adapters to Mitigate Multiple Dataset Biases},author={Liu, Yanchen and Yan, Jing and Chen, Yan and Liu, Jing and Wu, Hua},year={2022},publisher={ACL 2023},booktitle={ACL Workshop on Trustworthy Natural Language Processing, 2022},}
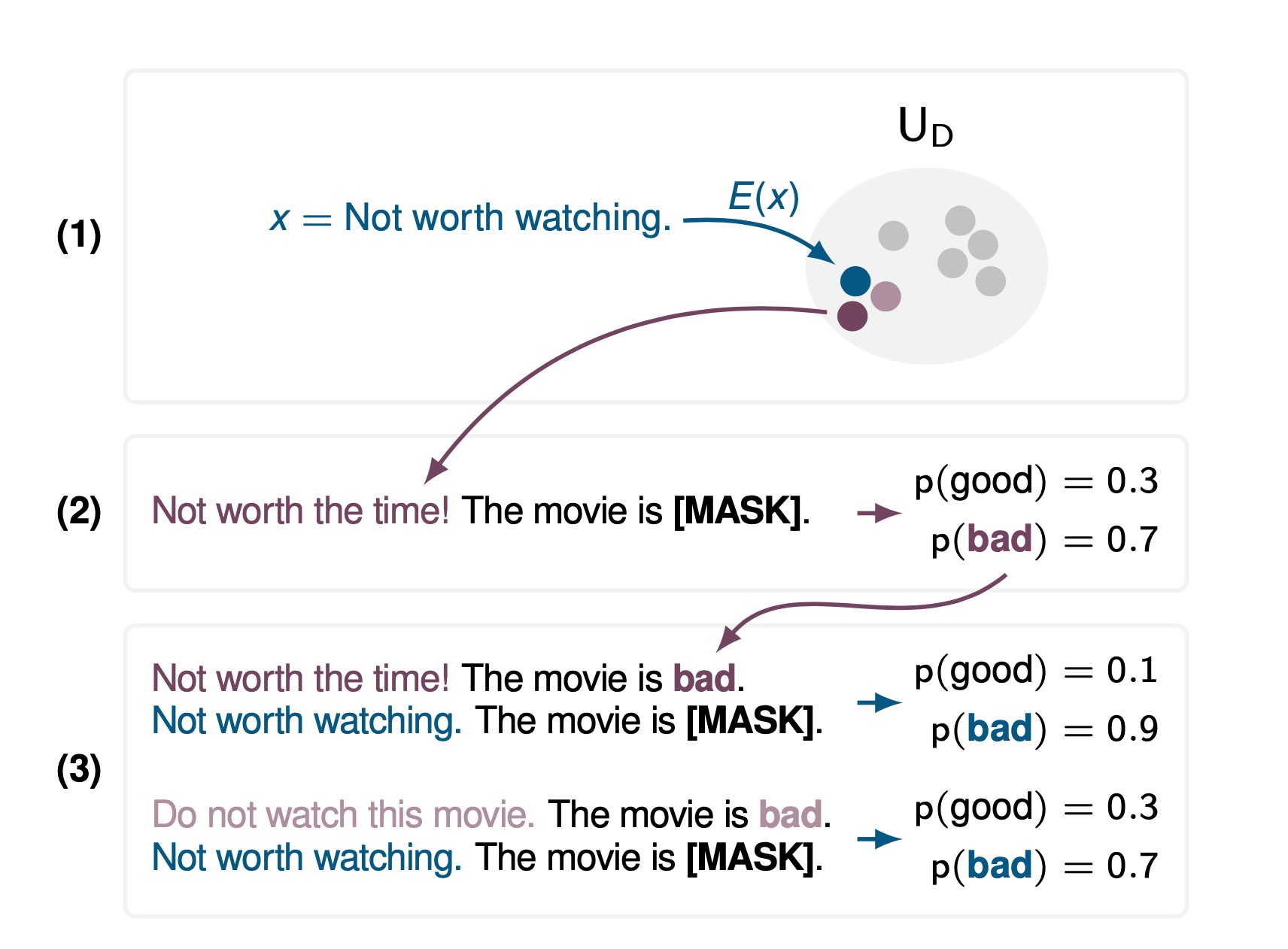
Semantic-Oriented Unlabeled Priming for Large-Scale Language Models
Due to the high costs associated with finetuning large language models, various recent works propose to adapt them to specific tasks without any parameter updates through in-context learning. Unfortunately, for in-context learning there is currently no way to leverage unlabeled data, which is often much easier to obtain in large quantities than labeled examples. In this work, we therefore investigate ways to make use of unlabeled examples to improve the zero-shot performance of pretrained language models without any finetuning: We introduce Semantic-Oriented Unlabeled Priming (SOUP), a method that classifies examples by retrieving semantically similar unlabeled examples, assigning labels to them in a zero-shot fashion, and then using them for in-context learning. We also propose bag-of-contexts priming, a new priming strategy that is more suitable for our setting and enables the usage of more examples than fit into the context window.
@inproceedings{Liu2022SemanticPriming,title={Semantic-Oriented Unlabeled Priming for Large-Scale Language Models},author={Liu, Yanchen and Schick, Timo and Schütze, Hinrich},year={2022},publisher={ACL 2023},booktitle={ACL Workshop on Simple and Efficient Natural Language Processing, 2022},}
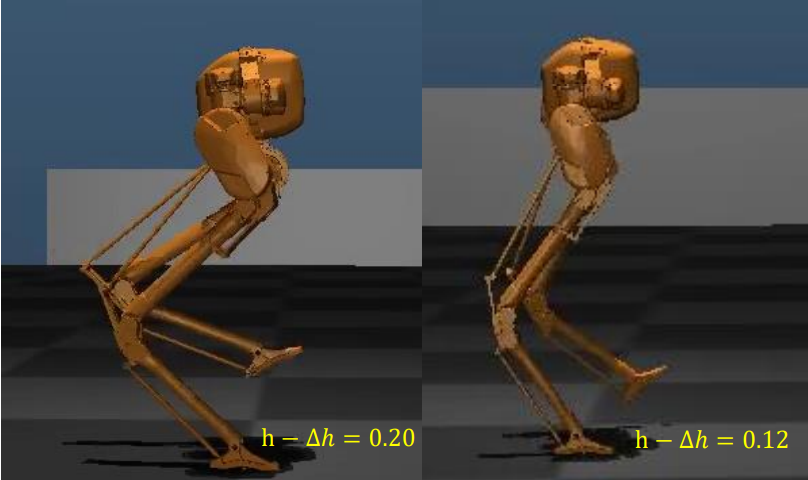
Custom Sine Waves Are Enough for Imitation Learning of Bipedal Gaits with Different Styles
Qi Wu*, Chong Zhang*, and Yanchen Liu
In IEEE International Conference on Mechatronics and Automation 2022
ICMA 2022 Finalists of Best Paper Award in Mechatronics
Not until recently, robust bipedal locomotion has been achieved through reinforcement learning. However, existing implementations rely heavily on insights and efforts from human experts, which is costly for the iterative design of robot systems. Also, styles of the learned motion are strictly limited to that of the reference. In this paper, we propose a new way to learn bipedal locomotion from a simple sine wave as the reference for foot heights. With the naive human insight that the two feet should be lifted up alternatively and periodically, we experimentally demonstrate on the Cassie robot that, a simple reward function is able to make the robot learn to walk end-to-end and efficiently without any explicit knowledge of the model. With custom sine waves, the learned gait pattern can also have customized styles.
@inproceedings{Wu2022CustomSineWaves,title={Custom Sine Waves Are Enough for Imitation Learning of Bipedal Gaits with Different Styles},author={Wu*, Qi and Zhang*, Chong and Liu, Yanchen},year={2022},publisher={IEEE International Conference on Mechatronics and Automation (ICMA) 2022. Finalists of Toshio Fukuda Best Paper Award in Mechatronics.},booktitle={IEEE International Conference on Mechatronics and Automation 2022},}